Phương pháp Ensemble Learning trong Machine Learning: Boosting, Bagging, Stacking (Sử dụng R code)
Trong machine learning tồn tại định lý “không có bữa trưa miễn phí” (No free lunch theorem), tức là không tồn tại một thuật toán mà luôn tốt cho mọi ứng dụng và mọi tập dữ liệu, vì các thuật toán machiner learning thường dựa trên một tập các tham số (hyperparameters) hoặc một giả thiết nhất định nào đó về phân bố dữ liệu. Vì vậy để tìm được những thuật toán phù hợp cho tập dataset của mình có thể các bạn sẽ cần nhiều thời gian để test các thuật toán khác nhau. Rồi từ đó thực hiện hiệu chỉnh các tham số (tuning hyperparameters) của thuật toán để thu được độ chính xác cao nhất.
Một cách khác có thể sử dụng để tăng độ chính xác trên tập dataset của bạn là kết hợp (combine) một số mô hình với nhau. Phương pháp này gọi là esemble learning. Ý tưởng của việc combine các mô hình khác nhau xuất phát từ một suy nghĩ hợp lý là: các mô hình khác nhau có khả năng khác nhau, có thể thực hiện tốt nhất các loại công việc khác nhau (subtasks), khi kết hợp các mô hình này với nhau một cách hợp lý thì sẽ tạo thành một mô hình kết hợp (combined model) mạnh có khả năng cải thiện hiệu suât tổng thể (overall performance) so với việc chỉ dùng các mô hình một cách đơn lẻ.
Các phương pháp Ensemble Learning được chia thành 3 loại sau đây:
Bagging(đóng bao)Boosting(tăng cường)Stacking(Xếp chồng)
Trong post này, trước hết tôi sẽ giới thiệu 3 kỹ thuật ensemble learning kể trên, sau đó là cách sử dụng thư viện caret và caretEnsemble trong R để triển khai chúng và áp dụng vào bài toán cụ thể.
Để cài đặt 2 thư viện này ta dùng lệnh install.packages(.) với tham số đầu vào là tên thư viện muốn cài:
install.packages("caret")
intall.packages("caretEnsemble")Đôi nét về thư viện caret: Ngôn ngữ R khác biệt bởi số lượng rất lớn các packages chuyên dụng khác nhau cho phép xây dựng các mô hình dự đoán. Tuy nhiên đây cũng chính là khuyết điểm, khi có quá nhiều các gói triển khai machine learning algorithms dưới dạng các
hàm rải rác đòi hỏi ta cần nhiều thời gian để tìm kiếm và nắm vững những đặc trưng về cú pháp cũng như cách sử dụng của từng hàm. Để giải quyết vấn đề này Max Kuhn đã xây dựng một giao diện phổ quát cho phép truy cập và sử dụng các machine learning algorithms từ cái gói khác nhau được triển khai trên ngôn ngữ R. Kết quả chính là package caret (viết tắt từ Classification and Regression Training), được công bố đầu tiên vào năm 2008 tại tạp chí phần mềm thống kê Journal of Statistical Software. Gói caret giúp chúng ta tiết kiệm được rất nhiều thời gian trong quá trình phân tích và xây dựng các models. Dưới đây là một số
đặc trưng cơ bản của gói caret:
Sử dụng cú pháp lệnh chung (phổ quát) không phụ thuộc vào cú pháp của các hàm gốc (các hàm triển khai các machine learningalgorithms)
Tự động tìm kiếm những giá trị tối ưu cho các
hyperparameterscủa mô hình (tuning parameters)Có khả năng tổ chức tính toán song song để tăng đáng kể tốc độ quá trình huấn luyện mô hình
Sử dụng
Caretcho phép giải quyết hầu hết các nhiệm vụ trongmachine learningtừ tiền xủ lý cho đến đánh giá mô hình
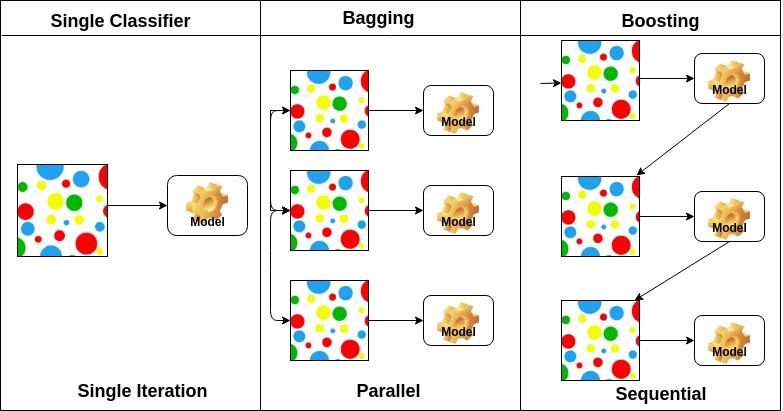
1. Phân biệt 3 kỹ thuật boosting, baggig và statcking
Bagging xây dựng một lượng lớn các models (thường là cùng loại) trên những subsamples khác nhau từ tập training dataset một cách song song nhằm đưa ra dự đoán tốt hơn.
Boosting xây dựng một lượng lớn các models (thường là cùng loại). Tuy nhiên quá trình huấn luyện trong phương pháp này diễn ra tuần tự theo chuỗi (sequence). Trong chuỗi này mỗi model sau sẽ học cách sửa những errors của model trước (hay nói cách khác là dữ liệu mà model trước dự đoán sai).
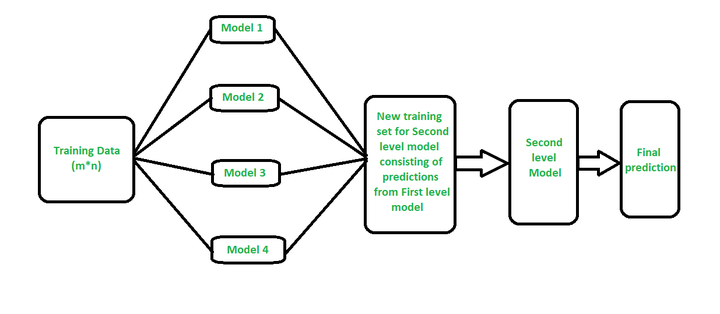
Stacking xây dựng một số models (thường là khác loại) và một mô hình supervisor model, mô hình này sẽ học cách kết hợp kết quả dự báo của một số mô hình một cách tốt nhất.
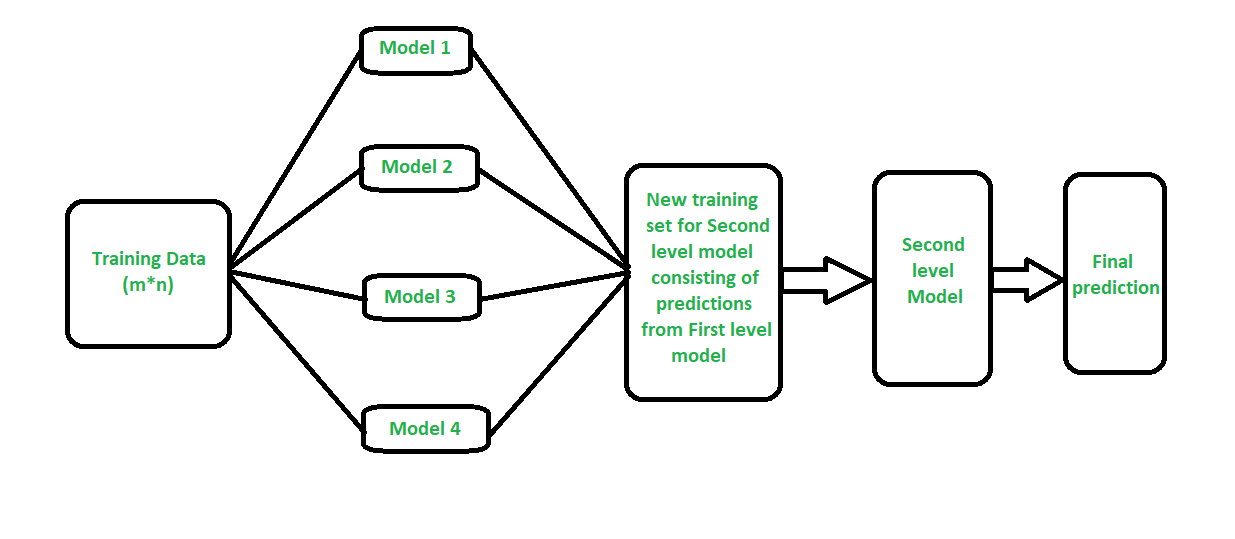
2. Thực hành
Nạp các thư viện cần dùng vào phiên làm việc của R để thực hành:
library(caret)
library(caretEnsemble) Kiểm tra số lượng các machine learning algorithms trong R được hỗ trợ bởi caret:
carets <- getModelInfo()
carets.names <- names(carets)
length(carets.names)## [1] 2382.1 Dữ liệu để thực hành
Để thực hành tôi lựa chọn bài toán phân loại nhị phân (binary classification) với tập dữ liệu ionoshene. Trong bài toán này chúng ta cần dự đoán xem cao tần trả vể từ năng lượng của các hạt trong khí quyển có cấu trúc hay là không. Để tìm hiểu thêm về bài toán này các bạn có thể đọc ở đây.
Load dữ liệu từ gói mlbench:
# Load the dataset
library(mlbench)
data(Ionosphere)
dataset <- Ionosphere2.1.1 Thống kê mô tả (descriptive statistics)
Kiểm tra kích thước tập dữ liệu:
dim(dataset)## [1] 351 35Kiểm tra cấu trúc của tập dữ liệu:
str(dataset)## 'data.frame': 351 obs. of 35 variables:
## $ V1 : Factor w/ 2 levels "0","1": 2 2 2 2 2 2 2 1 2 2 ...
## $ V2 : Factor w/ 1 level "0": 1 1 1 1 1 1 1 1 1 1 ...
## $ V3 : num 0.995 1 1 1 1 ...
## $ V4 : num -0.0589 -0.1883 -0.0336 -0.4516 -0.024 ...
## $ V5 : num 0.852 0.93 1 1 0.941 ...
## $ V6 : num 0.02306 -0.36156 0.00485 1 0.06531 ...
## $ V7 : num 0.834 -0.109 1 0.712 0.921 ...
## $ V8 : num -0.377 -0.936 -0.121 -1 -0.233 ...
## $ V9 : num 1 1 0.89 0 0.772 ...
## $ V10 : num 0.0376 -0.0455 0.012 0 -0.164 ...
## $ V11 : num 0.852 0.509 0.731 0 0.528 ...
## $ V12 : num -0.1776 -0.6774 0.0535 0 -0.2028 ...
## $ V13 : num 0.598 0.344 0.854 0 0.564 ...
## $ V14 : num -0.44945 -0.69707 0.00827 0 -0.00712 ...
## $ V15 : num 0.605 -0.517 0.546 -1 0.344 ...
## $ V16 : num -0.38223 -0.97515 0.00299 0.14516 -0.27457 ...
## $ V17 : num 0.844 0.055 0.838 0.541 0.529 ...
## $ V18 : num -0.385 -0.622 -0.136 -0.393 -0.218 ...
## $ V19 : num 0.582 0.331 0.755 -1 0.451 ...
## $ V20 : num -0.3219 -1 -0.0854 -0.5447 -0.1781 ...
## $ V21 : num 0.5697 -0.1315 0.7089 -0.6997 0.0598 ...
## $ V22 : num -0.297 -0.453 -0.275 1 -0.356 ...
## $ V23 : num 0.3695 -0.1806 0.4339 0 0.0231 ...
## $ V24 : num -0.474 -0.357 -0.121 0 -0.529 ...
## $ V25 : num 0.5681 -0.2033 0.5753 1 0.0329 ...
## $ V26 : num -0.512 -0.266 -0.402 0.907 -0.652 ...
## $ V27 : num 0.411 -0.205 0.59 0.516 0.133 ...
## $ V28 : num -0.462 -0.184 -0.221 1 -0.532 ...
## $ V29 : num 0.2127 -0.1904 0.431 1 0.0243 ...
## $ V30 : num -0.341 -0.116 -0.174 -0.201 -0.622 ...
## $ V31 : num 0.4227 -0.1663 0.6044 0.2568 -0.0571 ...
## $ V32 : num -0.5449 -0.0629 -0.2418 1 -0.5957 ...
## $ V33 : num 0.1864 -0.1374 0.5605 -0.3238 -0.0461 ...
## $ V34 : num -0.453 -0.0245 -0.3824 1 -0.657 ...
## $ Class: Factor w/ 2 levels "bad","good": 2 1 2 1 2 1 2 1 2 1 ...Hiển thị 5 hàng dữ liệu đầu tiên:
head(dataset, 5)## V1 V2 V3 V4 V5 V6 V7 V8 V9 V10
## 1 1 0 0.99539 -0.05889 0.85243 0.02306 0.83398 -0.37708 1.00000 0.03760
## 2 1 0 1.00000 -0.18829 0.93035 -0.36156 -0.10868 -0.93597 1.00000 -0.04549
## 3 1 0 1.00000 -0.03365 1.00000 0.00485 1.00000 -0.12062 0.88965 0.01198
## 4 1 0 1.00000 -0.45161 1.00000 1.00000 0.71216 -1.00000 0.00000 0.00000
## 5 1 0 1.00000 -0.02401 0.94140 0.06531 0.92106 -0.23255 0.77152 -0.16399
## V11 V12 V13 V14 V15 V16 V17 V18 V19
## 1 0.85243 -0.17755 0.59755 -0.44945 0.60536 -0.38223 0.84356 -0.38542 0.58212
## 2 0.50874 -0.67743 0.34432 -0.69707 -0.51685 -0.97515 0.05499 -0.62237 0.33109
## 3 0.73082 0.05346 0.85443 0.00827 0.54591 0.00299 0.83775 -0.13644 0.75535
## 4 0.00000 0.00000 0.00000 0.00000 -1.00000 0.14516 0.54094 -0.39330 -1.00000
## 5 0.52798 -0.20275 0.56409 -0.00712 0.34395 -0.27457 0.52940 -0.21780 0.45107
## V20 V21 V22 V23 V24 V25 V26 V27
## 1 -0.32192 0.56971 -0.29674 0.36946 -0.47357 0.56811 -0.51171 0.41078
## 2 -1.00000 -0.13151 -0.45300 -0.18056 -0.35734 -0.20332 -0.26569 -0.20468
## 3 -0.08540 0.70887 -0.27502 0.43385 -0.12062 0.57528 -0.40220 0.58984
## 4 -0.54467 -0.69975 1.00000 0.00000 0.00000 1.00000 0.90695 0.51613
## 5 -0.17813 0.05982 -0.35575 0.02309 -0.52879 0.03286 -0.65158 0.13290
## V28 V29 V30 V31 V32 V33 V34 Class
## 1 -0.46168 0.21266 -0.34090 0.42267 -0.54487 0.18641 -0.45300 good
## 2 -0.18401 -0.19040 -0.11593 -0.16626 -0.06288 -0.13738 -0.02447 bad
## 3 -0.22145 0.43100 -0.17365 0.60436 -0.24180 0.56045 -0.38238 good
## 4 1.00000 1.00000 -0.20099 0.25682 1.00000 -0.32382 1.00000 bad
## 5 -0.53206 0.02431 -0.62197 -0.05707 -0.59573 -0.04608 -0.65697 goodKiểm tra missing values trong dữ liệu:
sum(is.na(dataset))## [1] 0Kiểm tra phân phối của từng thuộc tính:
summary(dataset)## V1 V2 V3 V4 V5
## 0: 38 0:351 Min. :-1.0000 Min. :-1.00000 Min. :-1.0000
## 1:313 1st Qu.: 0.4721 1st Qu.:-0.06474 1st Qu.: 0.4127
## Median : 0.8711 Median : 0.01631 Median : 0.8092
## Mean : 0.6413 Mean : 0.04437 Mean : 0.6011
## 3rd Qu.: 1.0000 3rd Qu.: 0.19418 3rd Qu.: 1.0000
## Max. : 1.0000 Max. : 1.00000 Max. : 1.0000
## V6 V7 V8 V9
## Min. :-1.0000 Min. :-1.0000 Min. :-1.00000 Min. :-1.00000
## 1st Qu.:-0.0248 1st Qu.: 0.2113 1st Qu.:-0.05484 1st Qu.: 0.08711
## Median : 0.0228 Median : 0.7287 Median : 0.01471 Median : 0.68421
## Mean : 0.1159 Mean : 0.5501 Mean : 0.11936 Mean : 0.51185
## 3rd Qu.: 0.3347 3rd Qu.: 0.9692 3rd Qu.: 0.44567 3rd Qu.: 0.95324
## Max. : 1.0000 Max. : 1.0000 Max. : 1.00000 Max. : 1.00000
## V10 V11 V12 V13
## Min. :-1.00000 Min. :-1.00000 Min. :-1.00000 Min. :-1.0000
## 1st Qu.:-0.04807 1st Qu.: 0.02112 1st Qu.:-0.06527 1st Qu.: 0.0000
## Median : 0.01829 Median : 0.66798 Median : 0.02825 Median : 0.6441
## Mean : 0.18135 Mean : 0.47618 Mean : 0.15504 Mean : 0.4008
## 3rd Qu.: 0.53419 3rd Qu.: 0.95790 3rd Qu.: 0.48237 3rd Qu.: 0.9555
## Max. : 1.00000 Max. : 1.00000 Max. : 1.00000 Max. : 1.0000
## V14 V15 V16 V17
## Min. :-1.00000 Min. :-1.0000 Min. :-1.00000 Min. :-1.0000
## 1st Qu.:-0.07372 1st Qu.: 0.0000 1st Qu.:-0.08170 1st Qu.: 0.0000
## Median : 0.03027 Median : 0.6019 Median : 0.00000 Median : 0.5909
## Mean : 0.09341 Mean : 0.3442 Mean : 0.07113 Mean : 0.3819
## 3rd Qu.: 0.37486 3rd Qu.: 0.9193 3rd Qu.: 0.30897 3rd Qu.: 0.9357
## Max. : 1.00000 Max. : 1.0000 Max. : 1.00000 Max. : 1.0000
## V18 V19 V20 V21
## Min. :-1.000000 Min. :-1.0000 Min. :-1.00000 Min. :-1.0000
## 1st Qu.:-0.225690 1st Qu.: 0.0000 1st Qu.:-0.23467 1st Qu.: 0.0000
## Median : 0.000000 Median : 0.5762 Median : 0.00000 Median : 0.4991
## Mean :-0.003617 Mean : 0.3594 Mean :-0.02402 Mean : 0.3367
## 3rd Qu.: 0.195285 3rd Qu.: 0.8993 3rd Qu.: 0.13437 3rd Qu.: 0.8949
## Max. : 1.000000 Max. : 1.0000 Max. : 1.00000 Max. : 1.0000
## V22 V23 V24 V25
## Min. :-1.000000 Min. :-1.0000 Min. :-1.00000 Min. :-1.0000
## 1st Qu.:-0.243870 1st Qu.: 0.0000 1st Qu.:-0.36689 1st Qu.: 0.0000
## Median : 0.000000 Median : 0.5318 Median : 0.00000 Median : 0.5539
## Mean : 0.008296 Mean : 0.3625 Mean :-0.05741 Mean : 0.3961
## 3rd Qu.: 0.188760 3rd Qu.: 0.9112 3rd Qu.: 0.16463 3rd Qu.: 0.9052
## Max. : 1.000000 Max. : 1.0000 Max. : 1.00000 Max. : 1.0000
## V26 V27 V28 V29
## Min. :-1.00000 Min. :-1.0000 Min. :-1.00000 Min. :-1.0000
## 1st Qu.:-0.33239 1st Qu.: 0.2864 1st Qu.:-0.44316 1st Qu.: 0.0000
## Median :-0.01505 Median : 0.7082 Median :-0.01769 Median : 0.4966
## Mean :-0.07119 Mean : 0.5416 Mean :-0.06954 Mean : 0.3784
## 3rd Qu.: 0.15676 3rd Qu.: 0.9999 3rd Qu.: 0.15354 3rd Qu.: 0.8835
## Max. : 1.00000 Max. : 1.0000 Max. : 1.00000 Max. : 1.0000
## V30 V31 V32 V33
## Min. :-1.00000 Min. :-1.0000 Min. :-1.000000 Min. :-1.0000
## 1st Qu.:-0.23689 1st Qu.: 0.0000 1st Qu.:-0.242595 1st Qu.: 0.0000
## Median : 0.00000 Median : 0.4428 Median : 0.000000 Median : 0.4096
## Mean :-0.02791 Mean : 0.3525 Mean :-0.003794 Mean : 0.3494
## 3rd Qu.: 0.15407 3rd Qu.: 0.8576 3rd Qu.: 0.200120 3rd Qu.: 0.8138
## Max. : 1.00000 Max. : 1.0000 Max. : 1.000000 Max. : 1.0000
## V34 Class
## Min. :-1.00000 bad :126
## 1st Qu.:-0.16535 good:225
## Median : 0.00000
## Mean : 0.01448
## 3rd Qu.: 0.17166
## Max. : 1.00000Thuộc tính thứ V2 chỉ có 1 giá trị là 0 nên có thể loại bỏ:
dataset$V2 <- NULLChuyển thuộc tính V1 từ factor sang numeric:
dataset$V1 <- as.numeric(as.character(dataset$V1))Kiểm tra mức độ tương quan (correlation) giữa các thuộc tính (do số lượng thuộc tính lớn nên tôi chỉ hiển thị tương quan giữa 6 thuộc tính đầu làm mẫu):
cor(dataset[,1:6])## V1 V3 V4 V5 V6 V7
## V1 1.000000000 0.30203392 -0.006528852 0.15615240 0.12760571 0.22186692
## V3 0.302033923 1.00000000 0.143364804 0.47658695 0.02576751 0.44025437
## V4 -0.006528852 0.14336480 1.000000000 0.00115185 -0.19030761 -0.05402953
## V5 0.156152397 0.47658695 0.001151850 1.00000000 0.03832312 0.59707508
## V6 0.127605707 0.02576751 -0.190307607 0.03832312 1.00000000 -0.01022692
## V7 0.221866916 0.44025437 -0.054029528 0.59707508 -0.01022692 1.000000002.1.2 Trực quan hóa dữ liệu (data visualization)
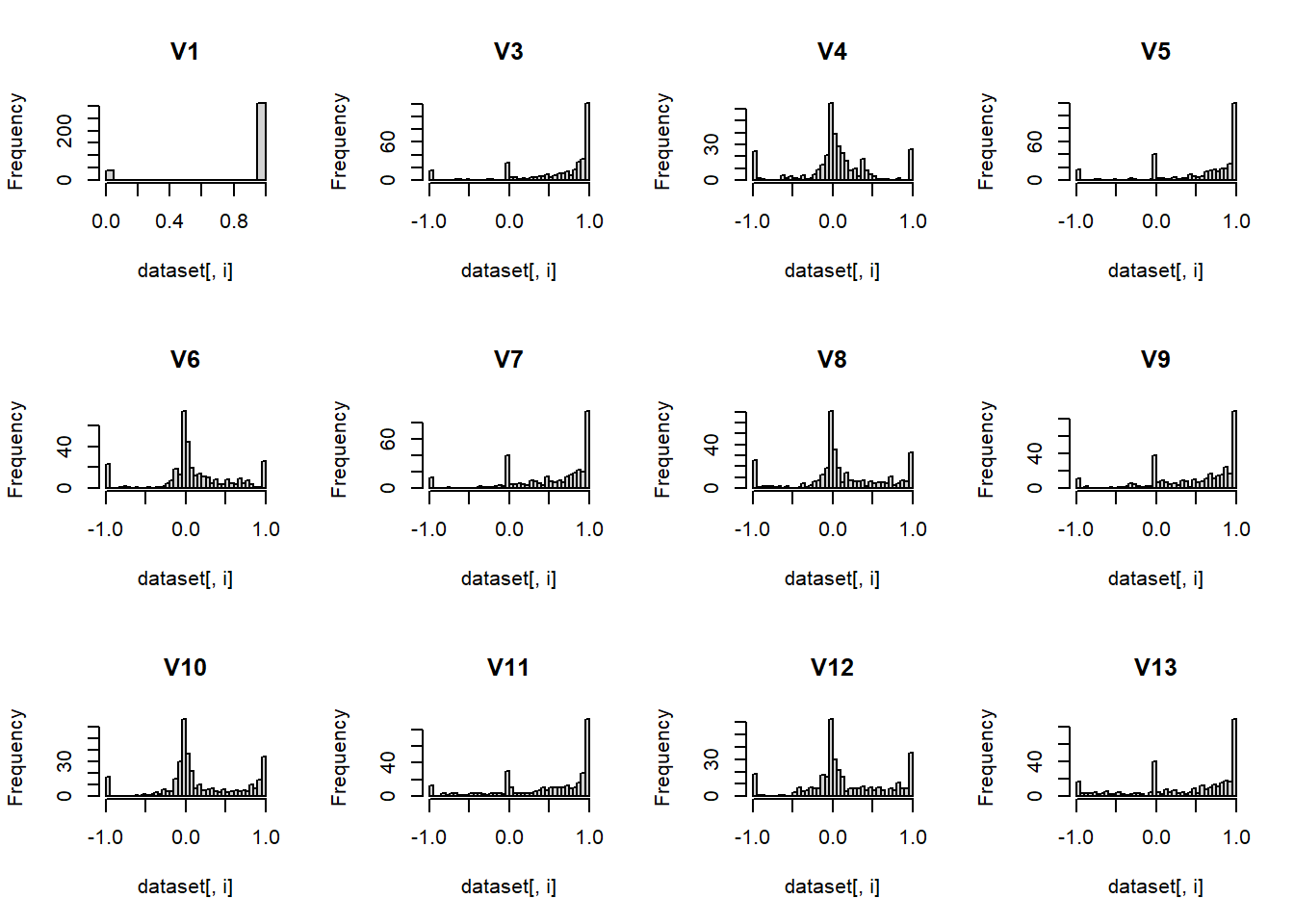
Do số lượng thuộc tính nhiều nên tôi chỉ thực hiện data visualization đối 12 thuộc tính đầu của tập dữ liệu.
Histogram cho 12 thuộc tính đầu:
par(mfrow=c(3,4))
for(i in 1:12) {
hist(dataset[,i], main=names(dataset)[i], breaks = 30)
}
Boxplot cho 12 thuộc tính đầu:
boxplot(dataset[, 1:12], col = "orange", main = "Features Boxplot")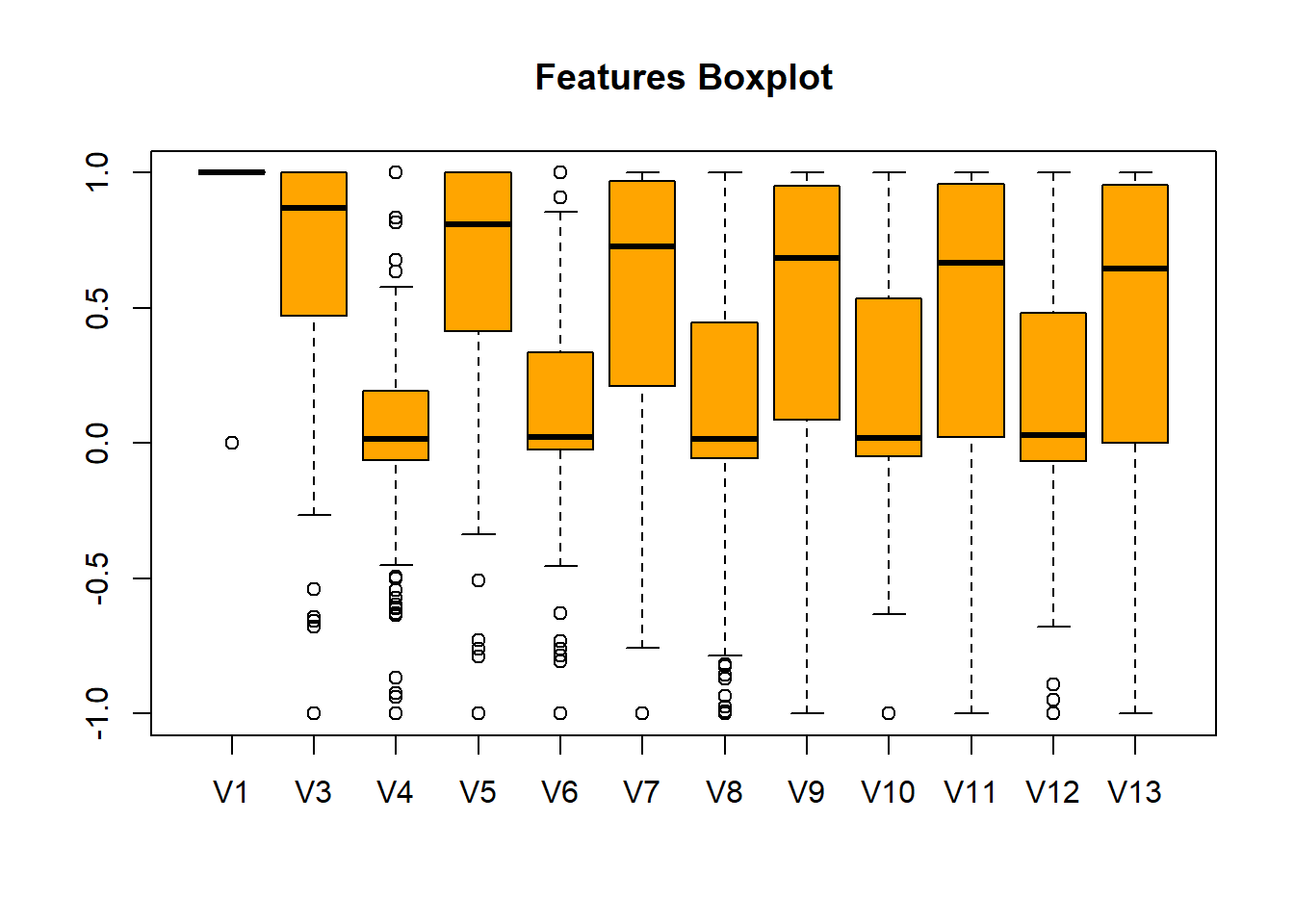
Trong bước này nếu phát hiện trong các thuộc tính có nhiều giá trị ngoại lai (outliers) thì các bạn có thể đọc post trước của tôi về cách loại bỏ outliers trong dữ liệu cho machine learning bằng các phương pháp thống kê tại đây.
2.1.3 Tiền xử lý dữ liệu (data preprocessing)
Xác định và Loại bỏ các thuộc tính tương quan với nhau cao (>0.75)
# Tìm các thuộc tính tương quan với nhau cao
cor_coefficient <- 0.75
correlations <- cor(dataset[,1:13])
highlyCorrelated <- findCorrelation(correlations, cutoff=cor_coefficient)
length(highlyCorrelated)## [1] 0Ở đây không có các thuộc tính tương quan cao với nhau, tuy nhiên nếu có thì các bạn có thể loại bỏ chúng như sau:
datasetFeatures <- dataset[,-highlyCorrelated]
dim(datasetFeatures)Chuẩn hóa giá trị của các thuộc tính (data normalization) về khoảng [0,1]:
preProcValues <- preProcess(dataset, method = c("range"))
data_processed <- predict(preProcValues, dataset)Vậy là dữ liệu của chúng ta đã sẵn sàng để test các thuật toán ensemble learning rồi.
2.2. Thuật toán Boosting
Trong phạm vi post này tôi sẽ test hai thuật toán boosting khá phổ biến là: C5.0 và Stochastic Gradient Boosting
Dưới đây là ví dụ huấn luyện hai mô hình này trên R với các tham số mặc định:
seed <- 10
# tạo một đối tượng control cho cross-validation
control <- trainControl(method="repeatedcv", number=10, repeats=3)
# Trong đó
# method = 'repeatedcv': sử dụng cross-validation với các tham số sau:
# number = 10 có nhĩa là quá trình cross-validation cần chia dữ liệu gốc thành 10 phần bằng nhau
# repeats = 3 có nhĩa là quá trình cross-validation sẽ hoàn thành sau 3 lần
# C5.0
set.seed(seed)
fit.c50 <- train(Class~., data=dataset, method="C5.0", metric = "Accuracy", trControl=control)
# Stochastic Gradient Boosting
set.seed(seed)
fit.gbm <- train(Class~., data=dataset, method="gbm", metric = "Accuracy", trControl=control, verbose=FALSE)So sánh kết quả hai mô hình:
boosting_results <- resamples(list(c5.0=fit.c50, gbm=fit.gbm))
summary(boosting_results)##
## Call:
## summary.resamples(object = boosting_results)
##
## Models: c5.0, gbm
## Number of resamples: 30
##
## Accuracy
## Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
## c5.0 0.8823529 0.9148810 0.9575163 0.9468627 0.9714286 1 0
## gbm 0.8529412 0.9166667 0.9428571 0.9420184 0.9714286 1 0
##
## Kappa
## Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
## c5.0 0.7213115 0.8157164 0.9069808 0.8806722 0.937833 1 0
## gbm 0.6586345 0.8142060 0.8776224 0.8707906 0.937201 1 0dotplot(boosting_results)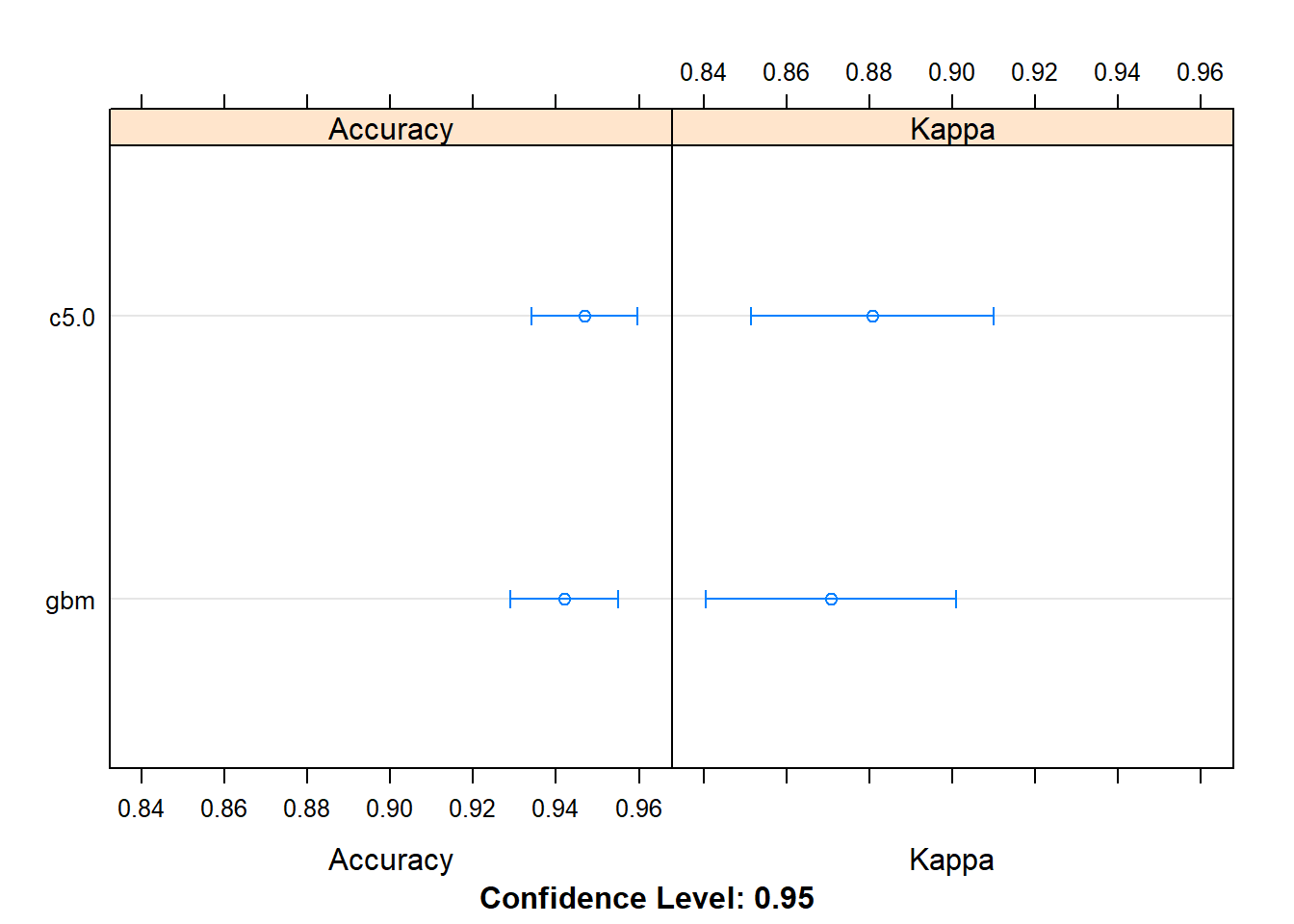
Từ kết quả so sánh ta thấy thuật toán C5.0 cho kết quả chính xác hơn so với Stochastic Gradient Boosting trong bài toán này (với độ chính xác là 94.68%)
2.3 Thuật toán Bagging
Chúng ta cùng test hai thuật toán thuộc kỹ thuật Bagging là: Bagged CART và Random Forest
Dưới đây là ví dụ huấn luyện hai mô hình này trên R với các tham số mặc định:
control <- trainControl(method="repeatedcv", number=10, repeats=3)
# Bagged CART
set.seed(seed)
fit.treebag <- train(Class~., data=dataset, method="treebag", metric = "Accuracy", trControl=control)
# Random Forest
set.seed(seed)
fit.rf <- train(Class~., data=dataset, method="rf", metric = "Accuracy", trControl=control)So sánh kết quả hai mô hình:
bagging_results <- resamples(list(treebag=fit.treebag, rf=fit.rf))
summary(bagging_results)##
## Call:
## summary.resamples(object = bagging_results)
##
## Models: treebag, rf
## Number of resamples: 30
##
## Accuracy
## Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
## treebag 0.8285714 0.8922269 0.9428571 0.9210566 0.9440476 0.9722222 0
## rf 0.8235294 0.9142857 0.9428571 0.9343946 0.9714286 1.0000000 0
##
## Kappa
## Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
## treebag 0.6209386 0.7708291 0.8731884 0.8266350 0.8770749 0.9407895 0
## rf 0.5984252 0.8149436 0.8734173 0.8550575 0.9372010 1.0000000 0dotplot(bagging_results)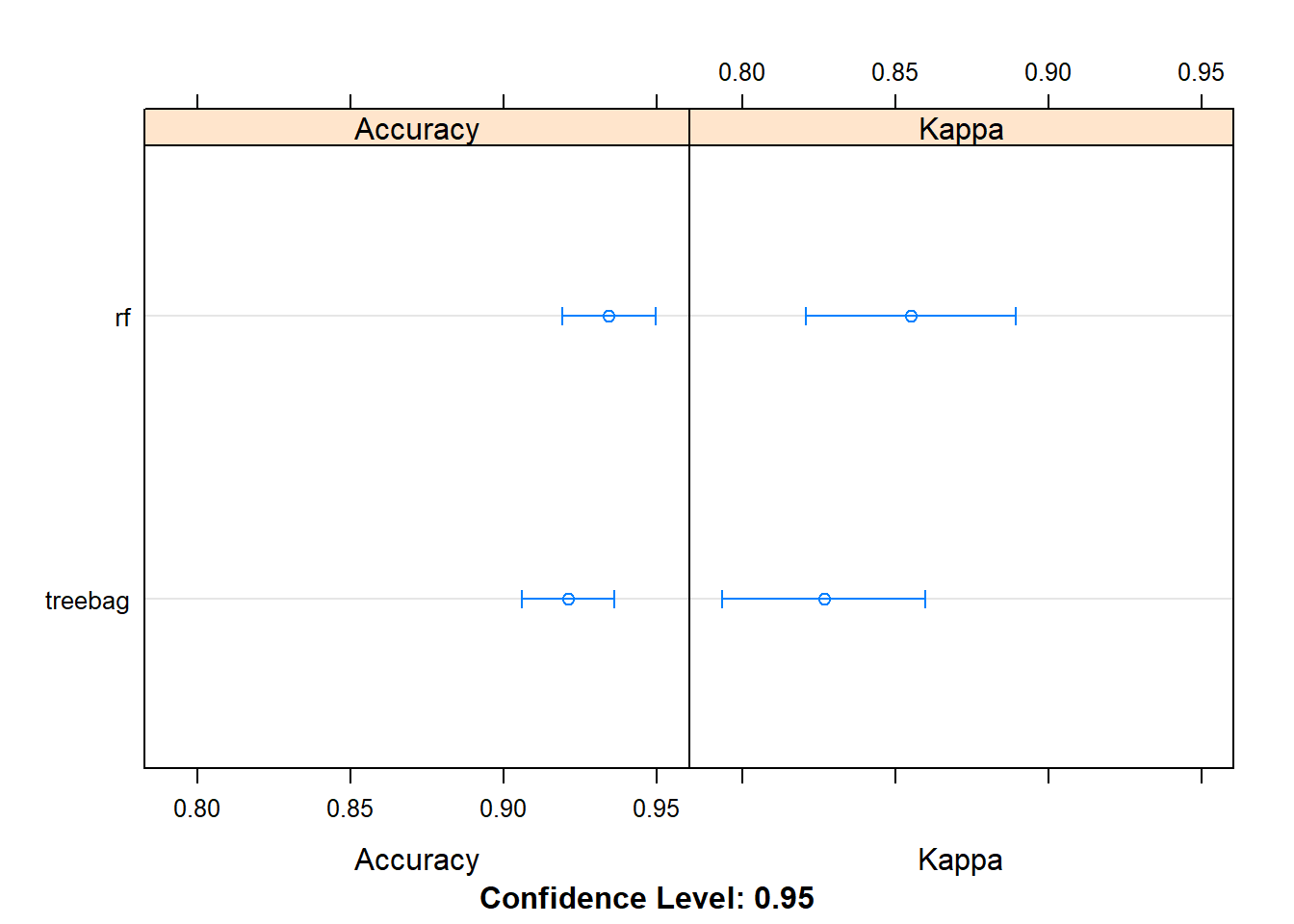
Từ kết quả so sánh ta thấy thuật toán Random Forest cho kết quả chính xác hơn so với CART trong bài toán này (với độ chính xác là 93.44%). Tuy nhiên cả hai thuật toán Bagging đều có độ chính xác nhỏ hơn so với 2 thuật toán Boosting trước.
2.4. Thuật toán Stacking
Để kết hợp các mô hình machine learning khác nhau trong R chúng ta sử dụng thư viện caretEnsemble. Với danh sách các caret models, hàm caretStack() của gói này có thể sự dụng để chỉ định mô hình bậc cao hơn, từ đó sẽ học cách tìm sự kết hợp tốt nhất những sub-models với nhau.
Ở ví dụ này, tôi sẽ sử dụng 5 sub-models sau cho tập dữ liệu ionosphere:
Linear Discriminate Analysis (
LDA)Classification and Regression Trees (
CART)Logistic Regression (
GLM)k-Nearest Neighbors (
kNN)Support Vector Machine with a Radial Basis Kernel Function (
SVM)
Dưới đây là ví dụ huấn luyện 5 mô hình này trên R với các tham số mặc định:
control <- trainControl(method="repeatedcv", number=10, repeats=3, savePredictions=TRUE, classProbs=TRUE)
algorithmList <- c('lda', 'rpart', 'glm', 'knn', 'svmRadial')
set.seed(seed)
models <- caretList(Class~., data=dataset, trControl=control, methodList=algorithmList)So sánh kết quả các mô hình:
results <- resamples(models)
summary(results)##
## Call:
## summary.resamples(object = results)
##
## Models: lda, rpart, glm, knn, svmRadial
## Number of resamples: 30
##
## Accuracy
## Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
## lda 0.7941176 0.8297619 0.8571429 0.8669546 0.9136555 0.9428571 0
## rpart 0.8000000 0.8529412 0.8611111 0.8736819 0.9079365 0.9714286 0
## glm 0.7428571 0.8539916 0.8823529 0.8824214 0.9166667 0.9714286 0
## knn 0.7500000 0.8235294 0.8333333 0.8403097 0.8601190 0.9444444 0
## svmRadial 0.8888889 0.9142857 0.9436508 0.9477591 0.9714286 1.0000000 0
##
## Kappa
## Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
## lda 0.4803493 0.6048824 0.6697323 0.6868903 0.8032314 0.8679245 0
## rpart 0.5648313 0.6586345 0.7024010 0.7193438 0.7900135 0.9397590 0
## glm 0.4578313 0.6618591 0.7267975 0.7371380 0.8163265 0.9368030 0
## knn 0.4087591 0.5641026 0.6196004 0.6199654 0.6770575 0.8754325 0
## svmRadial 0.7419355 0.8142060 0.8776224 0.8847121 0.9375755 1.0000000 0dotplot(results)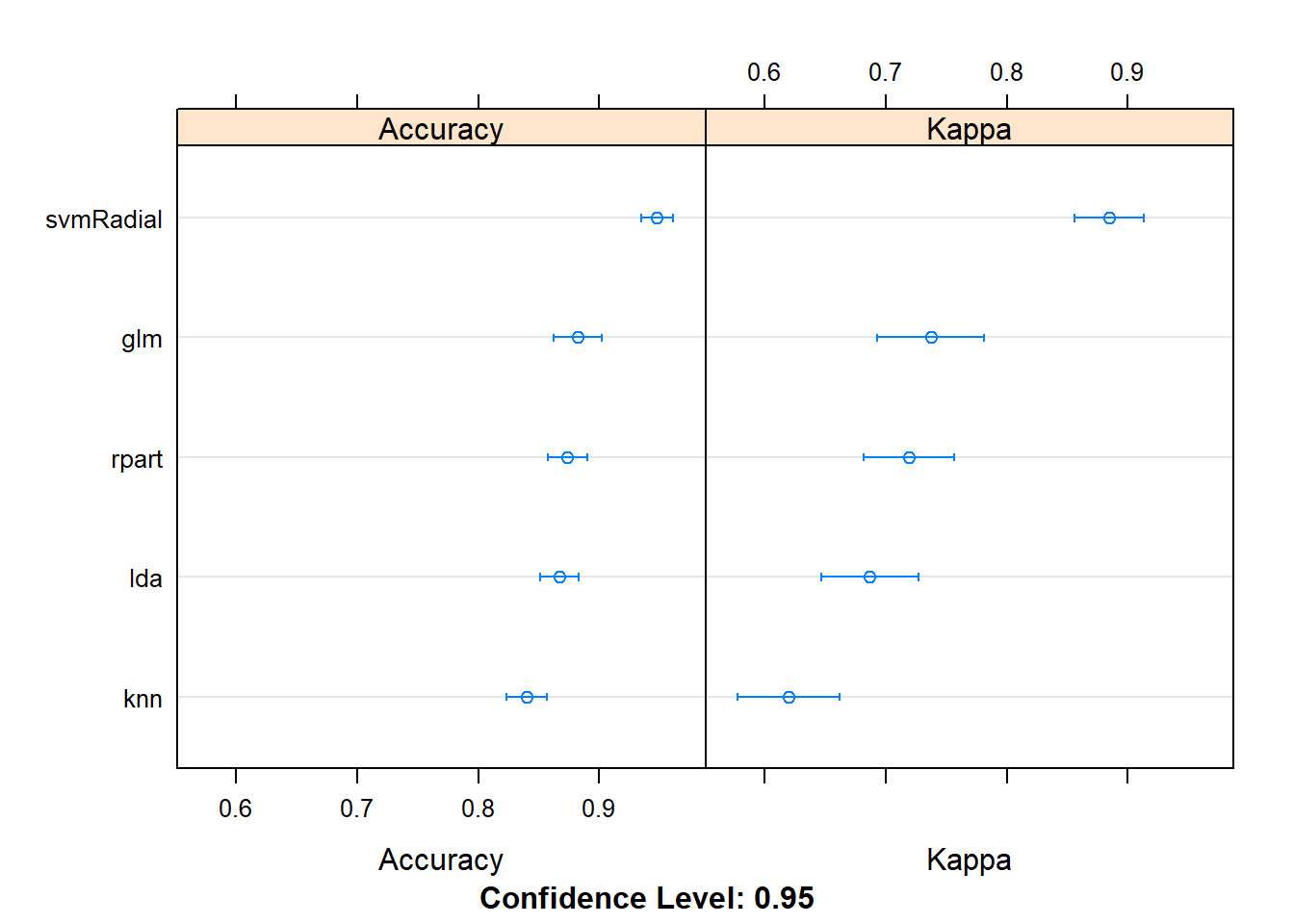
Ta thấy trong các mô hình này thì SVM cho kết quả chính xác nhất (94.78%).
Giờ chúng ta hãy thử dùng kỹ thuật stacking để xem có thể cải thiện được độ chính xác không.
Lưu ý: Khi các bạn muốn kết hợp các mô hình với nhau sử dụng kỹ thuật stacking, thì các bạn cần kiểm chứng rằng kết quả dự báo từ các mô hình này tương quan với nhau thấp. Nếu kết quả dự báo của các sub-models tương quan cao với nhau (> 0.75) thì có nghĩa là chúng sẽ cho kết quả dự báo tương tự nhau, điều này sẽ làm giảm hiệu quả khi ta kết hợp các mô hình này với nhau.
Kiểm tra độ tương quan giữa các sub-models:
modelCor(results)## lda rpart glm knn svmRadial
## lda 1.0000000 0.379461533 0.277037721 0.4898435 0.3056838
## rpart 0.3794615 1.000000000 0.001889458 0.4040556 0.2539580
## glm 0.2770377 0.001889458 1.000000000 0.1466240 0.4296011
## knn 0.4898435 0.404055597 0.146623958 1.0000000 0.5495574
## svmRadial 0.3056838 0.253957967 0.429601141 0.5495574 1.0000000splom(results)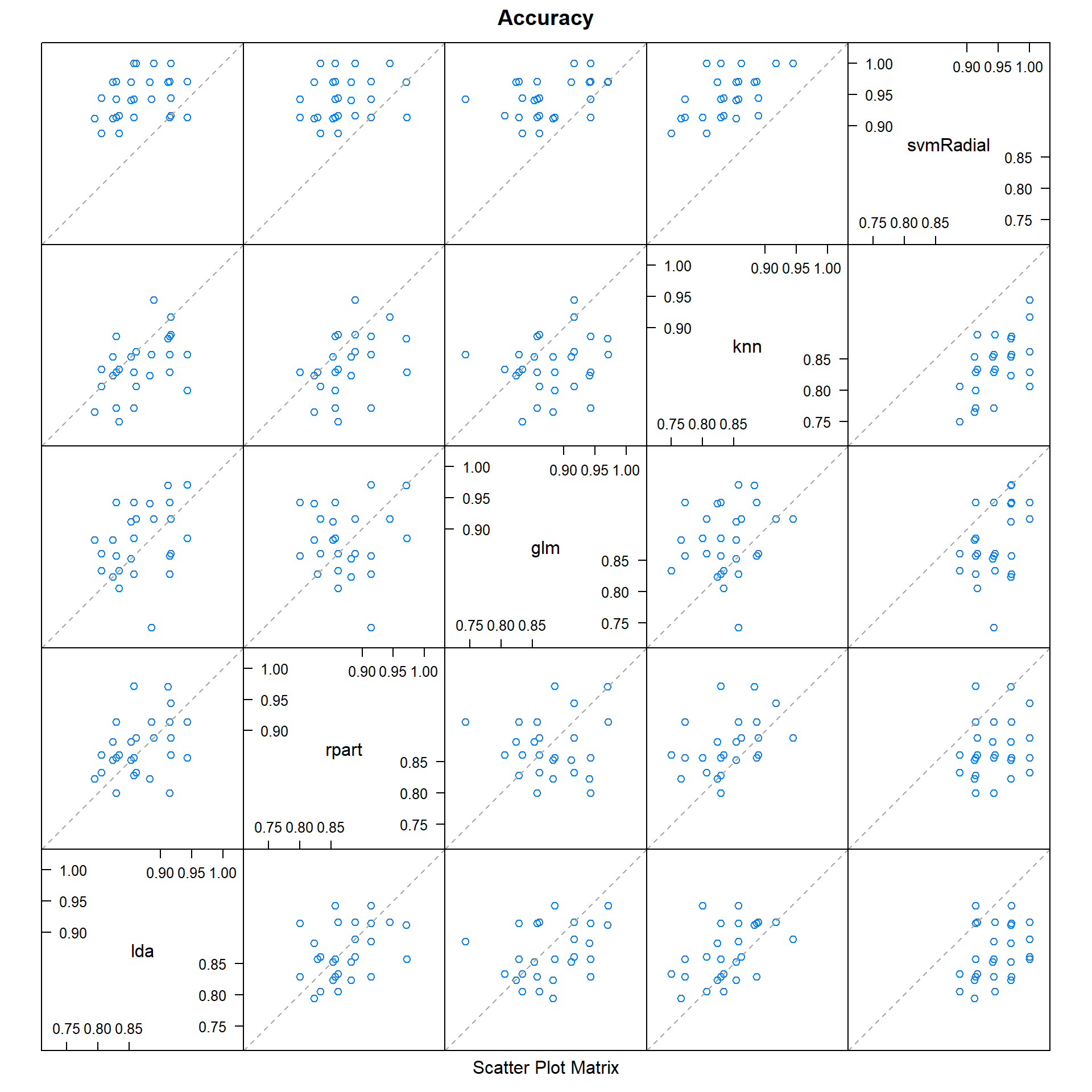
Nhìn vào kết quả ta có thể thấy các su-models cho kết quả dự báo tương quan với nhau thấp theo từng cặp. Cặp tương quan với nhau nhất là SVM và kNN với độ tương quan 0.549, cũng vẫn nhỏ hơn mức quy địn là cao (>0.75).
Nào chúng ta hãy thử kết hợp predictions của các sub-models sử dụng mô hình gml:
stackControl <- trainControl(method="repeatedcv", number=10, repeats=3, savePredictions=TRUE, classProbs=TRUE)
set.seed(seed)
stack.glm <- caretStack(models, method="glm", metric="Accuracy", trControl=stackControl)
print(stack.glm)## A glm ensemble of 5 base models: lda, rpart, glm, knn, svmRadial
##
## Ensemble results:
## Generalized Linear Model
##
## 1053 samples
## 5 predictor
## 2 classes: 'bad', 'good'
##
## No pre-processing
## Resampling: Cross-Validated (10 fold, repeated 3 times)
## Summary of sample sizes: 947, 947, 947, 948, 947, 949, ...
## Resampling results:
##
## Accuracy Kappa
## 0.9544285 0.9003902Độ chính xác cải thiện lên 95.44% so với chỉ sử dụng SVM model là 94.78%, tuy nhiên cũng chưa có độ chênh lệnh nhiều.
Tiếp theo tôi thử thử kết hợp predictions của các sub-models sử dụng mô hình random forest:
set.seed(seed)
stack.rf <- caretStack(models, method="rf", metric="Accuracy", trControl=stackControl)
print(stack.rf)## A rf ensemble of 5 base models: lda, rpart, glm, knn, svmRadial
##
## Ensemble results:
## Random Forest
##
## 1053 samples
## 5 predictor
## 2 classes: 'bad', 'good'
##
## No pre-processing
## Resampling: Cross-Validated (10 fold, repeated 3 times)
## Summary of sample sizes: 947, 947, 947, 948, 947, 949, ...
## Resampling results across tuning parameters:
##
## mtry Accuracy Kappa
## 2 0.9623381 0.9177343
## 3 0.9588700 0.9103978
## 5 0.9569833 0.9064705
##
## Accuracy was used to select the optimal model using the largest value.
## The final value used for the model was mtry = 2.Độ chính xác cũng cải thiện hơn so với chỉ dùng svm model (96.23%).
Tham khảo: How to Build an Ensemble Of Machine Learning Algorithms in R
Cuong Sai
PhD student
My research interests include Industrial AI (Intelligent predictive maintenance), Machine and Deep learning, Time series forecasting, Intelligent machinery fault diagnosis, Prognostics and health management, Error metrics / forecast evaluation.