Mở đầu về khoa học dữ liệu. So sánh các khái niệm khái niệm Artificial Intelligence, Machine Learning và Deep Learning
Khoa học dữ liệu (data science, DS) là một trong những ngành đang có nhu cầu tuyển dụng cao ở thời điểm hiện tại cũng như trong tương lai xa. Nhà khoa học dữ liệu (data scientist) được
Harvard Business Review đánh giá là “công việc hấp dẫn nhất thế kỷ 21”.
Vậy DS là gì? Trong thực tế một định nghĩa chính xác về DS không tồn tại, đây là một khái niệm liên ngành và rất rộng. DS là một lĩnh vực về các quá trình và các hệ thống trích rút tri thức hoặc hiểu biết dữ liệu ở các dạng khác nhau với biên độ rộng của các ngành như: Toán học, khoa học thống kê, khoa học thông tin, khoa học máy tính và lĩnh vực chuyên môn cụ thể. Bao gồm xử lý tín hiệu, lý thuyết xác suất thống kê, học máy, khai phá dữ liệu, cơ sở dữ liệu, kỹ thuật thông tin, nhận dạng mẫu, trực quan dữ liệu, các phân tích dự đoán, lý thuyết quyết định, kho dữ liệu, nén dữ liệu, lập trình máy tính, trí tuệ nhân tạo và siêu máy tính. Có thể nói “Một nhà khoa học dữ liệu là người giỏi hơn về thống kê so với những kỹ sư phát triển phần mềm và giỏi hơn về lập trình so với những nhà thống kê học.” Về bản chất có thể hiểu khoa học dữ liệu là ngành giúp chúng ta tạo ra giá trị từ dữ liệu với hai nhiệm vụ chính:
- Thu thập và xử lý dữ liệu để tìm ra những insights có giá trị.
- Giải thích, trình bày những insights đó cho các bên có liên quan để chuyển hóa isights thành hành động.
Xuât phát từ tên gọi DS ta có hai thành phần cấu thành là data và science:
-
Data: Là thành phần thứ nhất của cụm từ data science, thiếu nó thì tất cả các quá trình tiếp theo đều không thể thực hiện. Sau khi đã có đầy đủ dữ liệu cần thiết, trước khi sử dụng, công việc đầu tiên bạn cần làm là làm sạch và biến đổi dữ liệu - bước quan trọng nhất trong phân tích dữ liệu, nó chiếm đến 80% tổng số thời gian thực hiện phân tích.
-
Science: Chúng ta đã có dữ liệu vậy bây giờ làm gì với chúng? Đó là phân tích, trích rút các quy luật có ích và làm sao có để có thể sử dụng chúng một cách hiệu quả. Ở đây các lĩnh vực sẽ giúp chúng ta như là thống kê, máy học, học sâu, tối ưu. Máy học giúp chúng ta tìm ra các quy luật trong dữ liệu để có thể dự báo thông tin cần thiết với đối tượng mói sau đó.
DS và trí tuệ nhân tạo (Artificial Intelligence, AI) thường bị đánh tráo khái niệm. Để phân biệt chính xác khái niệm về hai công nghệ này cũng như các khái niệm trong AI, các bạn hãy cùng tham khảo bài viết nhé! Cuối bài tôi sẽ giới thiệu 1 số ngôn ngữ lập trình cho khoa học dữ liệu.
1 Phân biệt các khái niệm Data Scinece, Artificial Intelligence, machine learning và deep learning
Thực ra các lĩnh vực này đều có sự liên quan, chồng chéo đan xen với nhau. AI là một trong các công cụ cho DS. DS sử dụng AI trong các hoạt động của mình, tuy nhiên chắc chắn nó không bao hàm AI. Hay nói cách khác trong DS có sự đóng góp bởi một số khía cạnh của AI nhưng lại không phản ánh tất cả về AI. Hình dưới đây mô tả mối quan hệ của các khái niệm này:
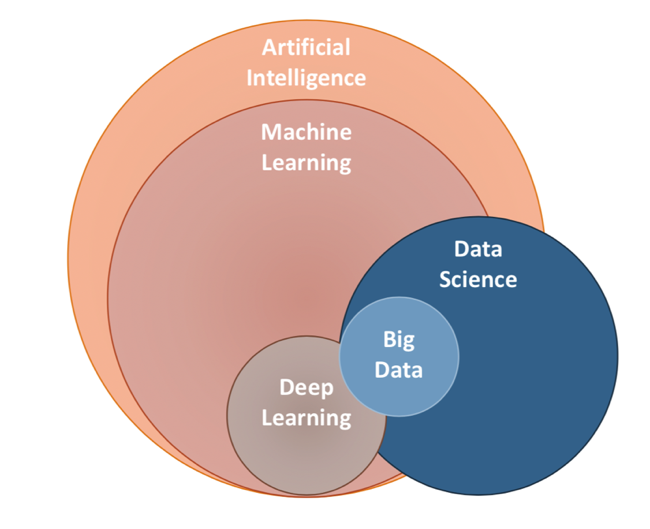
AI là một ngành khoa học được sinh ra với mục đích nhằm làm cho máy móc do con người tạo ra có những khả năng của trí tuệ và trí thông minh của con người - thông minh nhân tạo, tiêu biểu như biết suy nghĩ và lập luận để giải quyết vấn đề, biết giao tiếp do hiểu ngôn ngữ và tiếng nói, biết học và tự thích nghi,…. Ý tưởng về AI xuất hiện vào những năm 1950 khi một nhóm những người tiên phong trong lĩnh vực khoa học máy tính non trẻ tự đặt ra cho mình câu hỏi, liệu có thể làm cho máy tính biết suy nghĩ? - hệ quả của câu hỏi đó chính là những gì chúng ta đang học trong ngày hôm nay. Machine Learning và Deep Learning chính là phương tiện, công cụ để đạt được mục tiêu của AI.
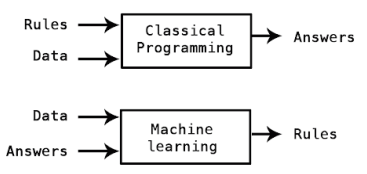
Để hiểu về Machine Learning và Deep Learning trước hết chúng ta hãy cùng tìm hiểu khái niệm học biểu diễn (representation learning) từ dữ liệu. Trong cuộc sống hàng ngày, hầu hết chúng ta đã quen thuộc với việc mô tả các sự vật, hiện tượng của thế giới bên ngoài qua các khái niệm, các con số, các giác quan,… Nhưng mô tả đó được gọi là các biểu diễn (representation) của sự vật, hiện tượng. Máy học (machine learning) cũng vậy, mục đích của nó là tìm cách biến đổi dữ liệu đầu vào thành các đầu ra có ý nghĩa. Hay nói một cách khoa học, một mô hình machine learning sẽ ánh xạ dữ liệu từ một không gian biểu diễn vào một không gian biểu diễn khác mà trên đó chúng ta có thể hiểu rõ hơn về dữ liệu ban đầu. Chính vì vậy machine learning được gọi là học biểu diễn (representation learning). Cách học này đã tạo ra một new programming paradigm. Trong lập trình truyền thống, con người nhập các quy tắc rules (program) và dữ liệu để xử lý theo các quy tắc đó để thu được answers. Còn trong Machine learning thì con người sẽ nhập dữ liệu và answers tương ứng với dữ liệu đó, còn ở đầu ra sẽ thu được các rules - các mô hình machine learning. Các mô hình này sau đó có thể sử dụng cho dữ liệu mới để thu được các answers. Trong machine learning hệ thống sẽ được huấn luyện thay vì lập trình rõ ràng. Nhiệm vụ chính của Machine learning chính là tự động tìm các phương pháp biến đổi dữ liệu đầu vào. Các phương pháp này có thể là thay đổi hệ tọa độ, hay là xử dụng các phép chiếu,…
Cùng một sự vật, hiện tượng có thể có nhiều cách biểu diễn khác nhau. Deep Learning ở đây cũng vậy, nó chính là một ngành nhỏ của Machine Learning: xử dụng cách tiếp cận mởi để tìm kiếm phương thức biểu diễn dữ liệu - bằng cách học liên tiếp các qua các lớp (layers) hay gọi là mạng thần kinh nhân tạo (Neural Network). Chữ Deep trong Deep Learning không có nghĩa là phương pháp này cho phép hiểu sâu hơn, mà chỉ để thể hiện cách biểu diễn dữ liệu qua nhiều lớp. Số lượng các lớp tạo thành một mô hình deep learning được gọi là chiều sâu (depth) của mô hình đó.
2 Ngôn ngữ lập trình cho khoa học dữ liệu
Chọn ngôn ngữ nào để bắt đầu sự nghiệp Khoa học dữ liệu sẽ có nhiều thử thách đối với bạn. Có một số ngôn ngữ phục vụ cho ngành này phải kể đến những ngôn ngữ lập trình sau:
R: là một trong những platforms mạnh cho học máy, thống kê và phân tích dữ liệu được phát triển và sử dụng bởi các nhà khoa học thống kê và phân tích dữ liệu hàng đầu trên thế giới. Nếu bạn muốn đi sâu vào phân tích dữ liệu và thống kê, thì R là ngôn ngữ dành cho bạn.Ngôn ngữ này đã có sự tăng trưởng vượt bậc khi phân tích dữ liệu và khoa học dữ liệu trở nên phổ biến hơn trong những năm gần đây. Hàng năm, số lượng người dùng R tăng hơn 40% và ngày càng có nhiều cơ quan và tổ chức sử dụng R trong hoạt động phân tích thường nhật Tuy nhiên trong thời rian gần đây độ phổ biến của nó đã giảm đi một chút.
Python: là một ngôn ngữ lập trình đa mục đích, khá mạnh và bao gồm các công cụ có thể ứng dụng vào các môi trường yêu cầu hình tượng hoá mà có thể xuất hiện trên các trang web hoặc trên điện thoại. Python cung cấp hỗ trợ cho một số lượng lớn các thư viện học sâu như Pandas, Matplotlib, Tensorflow, Keras, scikit-learn, v.v. Để bắt đầu với ngành Data Science. Python là một trong những ngôn ngữ lập trình lý tưởng và nó cũng dễ đọc hơn R.
Java: Ngôn ngữ lập trình Java gần đây được xếp hạng một trong những ngôn ngữ được yêu thích và đa năng nhất để viết, dựa vào bản khảo sát từ WP Engine. Nó cũng là một ngôn ngữ lập trình đa mục đích, được thiết kế riêng để càng ít phụ thuộc vào việc thực thi càng tốt. Nó có thể được sử dụng để xây dựng mọi thứ, đặc biệt là các nền tảng có thể mở rộng, nền tảng đa luồng (multithread) và có nền tảng người dùng mạnh mẽ. ác framework như Apache Spark, Hadoop và Hive ngày càng phổ biến trong môi trường thương mại, làm cho Java trở thành một trong những ngôn ngữ được các nhà khoa học dữ liệu yêu cầu. Kiến thức về Java sẽ tạo điều kiện cho bạn điều chỉnh và duy trì các nền tảng dữ liệu lớn như Hadoop được viết bằng cùng một ngôn ngữ.
Ngoài ra còn một số ngôn ngữ khác như là Julia, Scala, …
Tham khảo:
The differences between Data Science, Artificial Intelligence, Machine Learning, and Deep Learning
Cuong Sai
PhD student
My research interests include Industrial AI (Intelligent predictive maintenance), Machine and Deep learning, Time series forecasting, Intelligent machinery fault diagnosis, Prognostics and health management, Error metrics / forecast evaluation.